The Basics of Single Node Parallel Computing
Chris Rackauckas
September 21st, 2020
Youtube Video Link
Moore's law was the idea that computers double in efficiency at fixed time points, leading to exponentially more computing power over time. This was true for a very long time.

However, sometime in the last decade, computer cores have stopped getting faster.
The technology that promises to keep Moore’s Law going after 2013 is known as extreme ultraviolet (EUV) lithography. It uses light to write a pattern into a chemical layer on top of a silicon wafer, which is then chemically etched into the silicon to make chip components. EUV lithography uses very high energy ultraviolet light rays that are closer to X-rays than visible light. That’s attractive because EUV light has a short wavelength—around 13 nanometers—which allows for making smaller details than the 193-nanometer ultraviolet light used in lithography today. But EUV has proved surprisingly difficult to perfect.
-MIT Technology Review
The answer to the “end of Moore's Law” is Parallel Computing. However, programs need to be specifically designed in order to adequately use parallelism. This lecture will describe at a very high level the forms of parallelism and when they are appropriate. We will then proceed to use shared-memory multithreading to parallelize the simulation of the discrete dynamical system.
Managing Threads
Concurrency vs Parallelism and Green Threads
There is a difference between concurrency and parallelism. In a nutshell:
Concurrency: Interruptability
Parallelism: Independentability
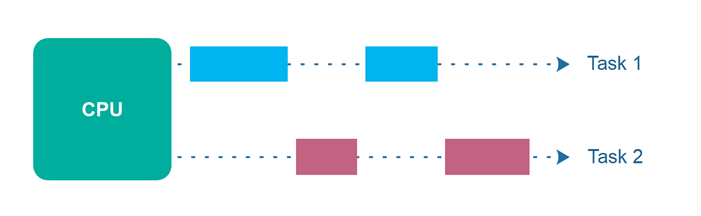
To start thinking about concurrency, we need to distinguish between a process and a thread. A process is discrete running instance of a computer program. It has allocated memory for the program's code, its data, a heap, etc. Each process can have many compute threads. These threads are the unit of execution that needs to be done. On each task is its own stack and a virtual CPU (virtual CPU since it's not the true CPU, since that would require that the task is ON the CPU, which it might not be because the task can be temporarily halted). The kernel of the operating systems then schedules tasks, which runs them. In order to keep the computer running smooth, context switching, i.e. changing the task that is actually running, happens all the time. This is independent of whether tasks are actually scheduled in parallel or not.

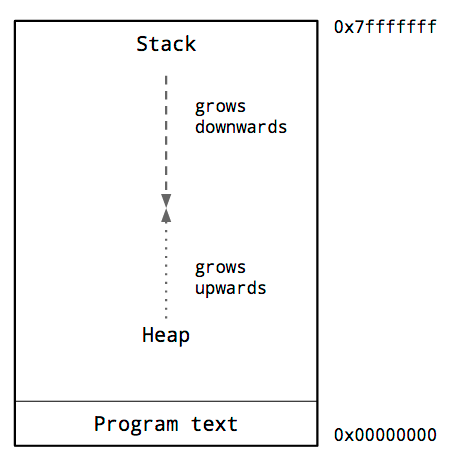
Each thread has its own stack associated with it.
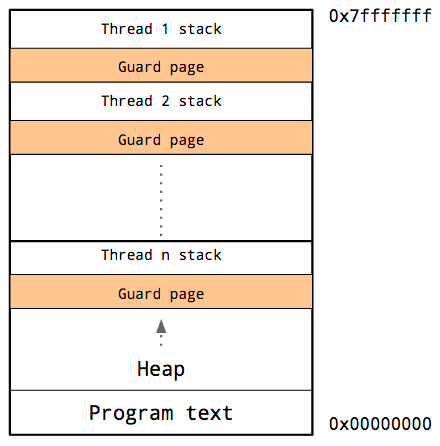
This is an important distinction because many tasks may need to run concurrently but without parallelism. Examples of this are input/output (I/O). For example, in a game you may want to be updating the graphics, but the moment a user clicks you want to handle that event. You do not necessarily need to have these running in parallel, but you need the event handling task to be running concurrently to the processing of the game.

Data handling is the key area of scientific computing where green threads (concurrent non-parallel threads) show up. For data handling, one may need to send a signal that causes a message to start being passed. Alternative hardware take over at that point. This alternative hardware is a processor specific for an I/O bus, like the controller for the SSD, modem, GPU, or Infiniband. It will be polled, then it will execute the command, and give the result. There are two variants:
Non-Blocking vs Blocking: Whether the thread will periodically poll for whether that task is complete, or whether it should wait for the task to complete before doing anything else
Synchronous vs Asynchronous: Whether to execute the operation as initiated by the program or as a response to an event from the kernel.
I/O operations cause a privileged context switch, allowing the task which is handling the I/O to directly be switched to in order to continue actions.
The Main Event Loop
Julia, along with other languages with a runtime (Javascript, Go, etc.) at its core is a single process running an event loop. This event loop is the main thread, and "Julia program" or "script" that one is running is actually ran in a green thread that is controlled by the main event loop. The event loop takes over to look for other work whenever the program hits a yield point. More yield points allows for more aggressive task switching, while it also means more switches to the event loop which suspends the numerical task, i.e. making it slower. Thus yielding shouldn't interrupt the main loop!
This is one area where languages can wildly differ in implementation. Languages structured for lots of I/O and input handling, like Javascript, have yield points at every line (it's an interpreted language and therefore the interpreter can always take control). In Julia, the yield points are minimized. The common yield points are allocations and I/O (println). This means that a tight non-allocating inner loop will not have any yield points and will be a thread that is not interruptible. While this is great for numerical performance, it is something to be aware of.
Side effect: if you run a long tight loop and wish to exit it, you may try Ctrl + C and see that it doesn't work. This is because interrupts are handled by the event loop. The event loop is never re-entered until after your tight numerical loop, and therefore you have the waiting occur. If you hit Ctrl + C multiple times, you will escalate the interruption until the OS takes over and then this is handled by the signal handling of the OS's event loop, which sends a higher level interrupt which Julia handles the moment the safety locks says it's okay (these locks occur during memory allocations to ensure that memory is not corrupted).
Asynchronous Calling Example
This example will become more clear when we get to distributed computing, but for now think of remotecall_fetch as a way to run a command on a different computer. What we want to do is start all of the commands at once, and then wait for all the results before finishing the loop. We will use @async to make the call to remotecall_fetch be non-blocking, i.e. it'll start the job and only poll infrequently to find out when the other machine has completed the job and returned the result. We then add @sync to the loop, which will only continue the loop after all of the green threads have fetched the result. Otherwise, it's possible that a[idx] may not be filled yet, since the thread may not have fetched the result!
@time begin a = Vector{Any}(undef,nworkers()) @sync for (idx, pid) in enumerate(workers()) @async a[idx] = remotecall_fetch(sleep, pid, 2) end end
The same can be done for writing to the disk. @async is a quick shorthand for spawning a green thread which will handle that I/O operation, and the main event loop will keep switching between them until they are all handled. @sync encodes that the program will not continue until all green threads are handled. This could be done more manually with Task and Channels, which will be something we touch on in the future.
Examples of the Differences
Synchronous = Thread will complete an action
Blocking = Thread will wait until action is completed
Asynchronous + Non-Blocking: I/O
Asynchronous + Blocking: Threaded atomics (demonstrated next lecture)
Synchronous + Blocking: Standard computing,
@syncSynchronous + Non-Blocking: Webservers where an I/O operation can be performed, but one never checks if the operation is completed.
Multithreading
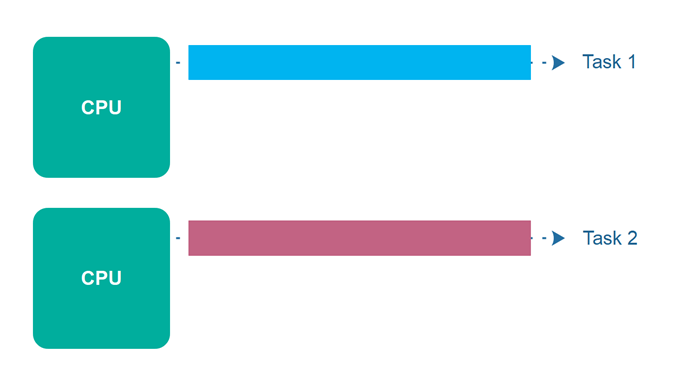
If your threads are independent, then it may make sense to run them in parallel. This is the form of parallelism known as multithreading. To understand the data that is available in a multithreaded setup, let's look at the picture of threads again:
Each thread has its own call stack, but it's the process that holds the heap. This means that dynamically-sized heap allocated objects are shared between threads with no cost, a setup known as shared-memory computing.
Loop-Based Multithreading with @threads
Let's look back at our Lorenz dynamical system from before:
using StaticArrays, BenchmarkTools function lorenz(u,p) α,σ,ρ,β = p @inbounds begin du1 = u[1] + α*(σ*(u[2]-u[1])) du2 = u[2] + α*(u[1]*(ρ-u[3]) - u[2]) du3 = u[3] + α*(u[1]*u[2] - β*u[3]) end @SVector [du1,du2,du3] end function solve_system_save!(u,f,u0,p,n) @inbounds u[1] = u0 @inbounds for i in 1:length(u)-1 u[i+1] = f(u[i],p) end u end p = (0.02,10.0,28.0,8/3) u = Vector{typeof(@SVector([1.0,0.0,0.0]))}(undef,1000) @btime solve_system_save!(u,lorenz,@SVector([1.0,0.0,0.0]),p,1000)
4.753 μs (0 allocations: 0 bytes)
1000-element Vector{SVector{3, Float64}}:
[1.0, 0.0, 0.0]
[0.8, 0.56, 0.0]
[0.752, 0.9968000000000001, 0.008960000000000001]
[0.80096, 1.3978492416000001, 0.023474005333333336]
[0.92033784832, 1.8180538219817644, 0.04461448495326095]
[1.099881043052353, 2.296260732619613, 0.07569952060880669]
[1.339156980965805, 2.864603692722823, 0.12217448583728006]
[1.6442463233172087, 3.5539673118971193, 0.19238159391549564]
[2.026190521033191, 4.397339452147425, 0.2989931959555302]
[2.5004203072560376, 5.431943011293093, 0.4612438424853632]
⋮
[6.8089180814322185, 0.8987564841782779, 31.6759436385101]
[5.6268857619814305, 0.3801973723631693, 30.108951163308078]
[4.577548084057778, 0.13525687944525802, 28.545926978224173]
[3.6890898431352737, 0.08257160199224252, 27.035860436772758]
[2.9677861949066675, 0.15205611935372762, 25.600040161309696]
[2.4046401797960795, 0.2914663505185634, 24.24373008707723]
[1.9820054139405763, 0.46628657468365653, 22.964748583050085]
[1.6788616460891923, 0.6565587545689172, 21.758445642263496]
[1.4744010677851374, 0.8530017039412324, 20.62004063423844]
In order to use multithreading on this code, we need to take a look at the dependency graph and see what items can be calculated independently of each other. Notice that
σ*(u[2]-u[1])
ρ-u[3]
u[1]*u[2]
β*u[3]are all independent operations, so in theory we could split those off to different threads, move up, etc.
Or we can have three threads:
u[1] + α*(σ*(u[2]-u[1]))
u[2] + α*(u[1]*(ρ-u[3]) - u[2])
u[3] + α*(u[1]*u[2] - β*u[3])all don't depend on the output of each other, so these tasks can be run in parallel. We can do this by using Julia's Threads.@threads macro which puts each of the computations of a loop in a different thread. The threaded loops do not allow you to return a value, so how do you build up the values for the @SVector?
...?
...?
...?
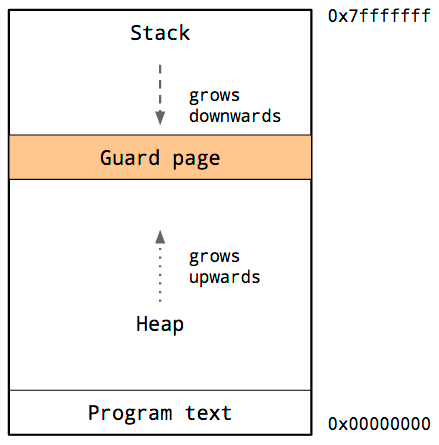
It's not possible! To understand why, let's look at the picture again:
There is a shared heap, but the stacks are thread local. This means that a value cannot be stack allocated in one thread and magically appear when re-entering the main thread: it needs to go on the heap somewhere. But if it needs to go onto the heap, then it makes sense for us to have preallocated its location. But if we want to preallocate du[1], du[2], and du[3], then it makes sense to use the fully non-allocating update form:
function lorenz!(du,u,p) α,σ,ρ,β = p @inbounds begin du[1] = u[1] + α*(σ*(u[2]-u[1])) du[2] = u[2] + α*(u[1]*(ρ-u[3]) - u[2]) du[3] = u[3] + α*(u[1]*u[2] - β*u[3]) end end function solve_system_save_iip!(u,f,u0,p,n) @inbounds u[1] = u0 @inbounds for i in 1:length(u)-1 f(u[i+1],u[i],p) end u end p = (0.02,10.0,28.0,8/3) u = [Vector{Float64}(undef,3) for i in 1:1000] @btime solve_system_save_iip!(u,lorenz!,[1.0,0.0,0.0],p,1000)
7.316 μs (2 allocations: 80 bytes)
1000-element Vector{Vector{Float64}}:
[1.0, 0.0, 0.0]
[0.8, 0.56, 0.0]
[0.752, 0.9968000000000001, 0.008960000000000001]
[0.80096, 1.3978492416000001, 0.023474005333333336]
[0.92033784832, 1.8180538219817644, 0.04461448495326095]
[1.099881043052353, 2.296260732619613, 0.07569952060880669]
[1.339156980965805, 2.864603692722823, 0.12217448583728006]
[1.6442463233172087, 3.5539673118971193, 0.19238159391549564]
[2.026190521033191, 4.397339452147425, 0.2989931959555302]
[2.5004203072560376, 5.431943011293093, 0.4612438424853632]
⋮
[6.8089180814322185, 0.8987564841782779, 31.6759436385101]
[5.6268857619814305, 0.3801973723631693, 30.108951163308078]
[4.577548084057778, 0.13525687944525802, 28.545926978224173]
[3.6890898431352737, 0.08257160199224252, 27.035860436772758]
[2.9677861949066675, 0.15205611935372762, 25.600040161309696]
[2.4046401797960795, 0.2914663505185634, 24.24373008707723]
[1.9820054139405763, 0.46628657468365653, 22.964748583050085]
[1.6788616460891923, 0.6565587545689172, 21.758445642263496]
[1.4744010677851374, 0.8530017039412324, 20.62004063423844]
and now we multithread:
using Base.Threads function lorenz_mt!(du,u,p) α,σ,ρ,β = p let du=du, u=u, p=p Threads.@threads for i in 1:3 @inbounds begin if i == 1 du[1] = u[1] + α*(σ*(u[2]-u[1])) elseif i == 2 du[2] = u[2] + α*(u[1]*(ρ-u[3]) - u[2]) else du[3] = u[3] + α*(u[1]*u[2] - β*u[3]) end nothing end end end nothing end function solve_system_save_iip!(u,f,u0,p,n) @inbounds u[1] = u0 @inbounds for i in 1:length(u)-1 f(u[i+1],u[i],p) end u end p = (0.02,10.0,28.0,8/3) u = [Vector{Float64}(undef,3) for i in 1:1000] @btime solve_system_save_iip!(u,lorenz_mt!,[1.0,0.0,0.0],p,1000);
3.720 ms (21980 allocations: 1.62 MiB)
Parallelism doesn't always make things faster. There are two costs associated with this code. For one, we had to go to the slower heap+mutation version, so its implementation starting point is slower. But secondly, and more importantly, the cost of spinning a new thread is non-negligible. In fact, here we can see that it even needs to make a small allocation for the new context. The total cost is on the order of 50ns: not huge, but something to take note of. So what we've done is taken almost free calculations and made them ~50ns by making each in a different thread, instead of just having it be one thread with one call stack.
The moral of the story is that you need to make sure that there's enough work per thread in order to effectively accelerate a program with parallelism.
Data-Parallel Problems
So not every setup is amenable to parallelism. Dynamical systems are notorious for being quite difficult to parallelize because the dependency of the future time step on the previous time step is clear, meaning that one cannot easily "parallelize through time" (though it is possible, which we will study later).
However, one common way that these systems are generally parallelized is in their inputs. The following questions allow for independent simulations:
What steady state does an input
u0go to for some list/region of initial conditions?How does the solution very when I use a different
p?
The problem has a few descriptions. For one, it's called an embarrassingly parallel problem since the problem can remain largely intact to solve the parallelism problem. To solve this, we can use the exact same solve_system_save_iip!, and just change how we are calling it. Secondly, this is called a data parallel problem, since it parallelized by splitting up the input data (here, the possible u0 or ps) and acting on them independently.
Multithreaded Parameter Searches
Now let's multithread our parameter search. Let's say we wanted to compute the mean of the values in the trajectory. For a single input pair, we can compute that like:
using Statistics function compute_trajectory_mean(u0,p) u = Vector{typeof(@SVector([1.0,0.0,0.0]))}(undef,1000) solve_system_save!(u,lorenz,u0,p,1000); mean(u) end @btime compute_trajectory_mean(@SVector([1.0,0.0,0.0]),p)
5.776 μs (4 allocations: 23.54 KiB)
3-element SVector{3, Float64} with indices SOneTo(3):
-0.31149962346484683
-0.3097490174897651
26.024603558583014
We can make this faster by preallocating the cache vector u. For example, we can globalize it:
u = Vector{typeof(@SVector([1.0,0.0,0.0]))}(undef,1000) function compute_trajectory_mean2(u0,p) # u is automatically captured solve_system_save!(u,lorenz,u0,p,1000); mean(u) end @btime compute_trajectory_mean2(@SVector([1.0,0.0,0.0]),p)
5.719 μs (3 allocations: 112 bytes)
3-element SVector{3, Float64} with indices SOneTo(3):
-0.31149962346484683
-0.3097490174897651
26.024603558583014
But this is still allocating? The issue with this code is that u is a global, and captured globals cannot be inferred because their type can change at any time. Thus what we can do instead is capture a constant:
const _u_cache = Vector{typeof(@SVector([1.0,0.0,0.0]))}(undef,1000) function compute_trajectory_mean3(u0,p) # u is automatically captured solve_system_save!(_u_cache,lorenz,u0,p,1000); mean(_u_cache) end @btime compute_trajectory_mean3(@SVector([1.0,0.0,0.0]),p)
5.679 μs (1 allocation: 32 bytes)
3-element SVector{3, Float64} with indices SOneTo(3):
-0.31149962346484683
-0.3097490174897651
26.024603558583014
Now it's just allocating the output. The other way to do this is to use a closure which encapsulates the cache data:
function _compute_trajectory_mean4(u,u0,p) solve_system_save!(u,lorenz,u0,p,1000); mean(u) end compute_trajectory_mean4(u0,p) = _compute_trajectory_mean4(_u_cache,u0,p) @btime compute_trajectory_mean4(@SVector([1.0,0.0,0.0]),p)
5.681 μs (1 allocation: 32 bytes)
3-element SVector{3, Float64} with indices SOneTo(3):
-0.31149962346484683
-0.3097490174897651
26.024603558583014
This is the same, but a bit more explicit. Now let's create our parameter search function. Let's take a sample of parameters:
ps = [(0.02,10.0,28.0,8/3) .* (1.0,rand(3)...) for i in 1:1000]
1000-element Vector{NTuple{4, Float64}}:
(0.02, 2.5332076437262483, 25.092426018021953, 2.5380321037364277)
(0.02, 1.0182181840217142, 3.4458170293316432, 2.1178522628174896)
(0.02, 8.618285806013878, 14.923360793551407, 0.48230663841905397)
(0.02, 8.170377707599156, 4.273461308425575, 1.9144457203372973)
(0.02, 0.7471618722634077, 7.95735926372641, 1.6152124476302445)
(0.02, 8.836239486232639, 11.959339227966584, 0.7531047951641672)
(0.02, 4.254262362615274, 11.701685551534743, 2.039747174150213)
(0.02, 9.529620755767453, 4.665223530167241, 0.6268641303544351)
(0.02, 1.7190694830646758, 4.224448639414806, 0.21406660938495242)
(0.02, 5.4651246130796896, 9.19412518651593, 0.44516380402248973)
⋮
(0.02, 5.810957300766106, 23.36270567250681, 1.8429675978063962)
(0.02, 6.63841042287681, 18.62663430831862, 0.9284895113803474)
(0.02, 1.3357998991676823, 11.31019454946305, 2.3190310754078682)
(0.02, 1.0905872574228814, 18.79024563606243, 1.2854790801283635)
(0.02, 0.9920109607113836, 19.14135297838192, 0.07163532882194801)
(0.02, 4.444161785146372, 15.279868418876855, 2.5422268242520025)
(0.02, 3.0525790396482435, 16.478001385245168, 2.558783133313492)
(0.02, 2.4839367101918386, 0.933380286202556, 1.8939404262519326)
(0.02, 3.596732529853277, 3.7340123593963557, 0.36090766817686265)
And let's get the mean of the trajectory for each of the parameters.
serial_out = map(p -> compute_trajectory_mean4(@SVector([1.0,0.0,0.0]),p),ps)
1000-element Vector{SVector{3, Float64}}:
[-0.31512668920231524, -0.3045138879625728, 15.13591047755129]
[2.177955141931815, 2.2406104155346003, 2.2811099481057435]
[-0.17816534876221382, -0.17915492475972628, 13.295158163066247]
[2.4338902920147403, 2.443090275116142, 3.1098887608701]
[3.2479403841568795, 3.4053530491931636, 6.6569065080195635]
[0.1340233447046131, 0.1176530001662119, 9.886646312110699]
[-3.4586519778669427, -3.5423755969016426, 9.192437966261833]
[1.4050633756096162, 1.4075995888795731, 3.4619290919671513]
[-0.30013594952125694, -0.3473918853474649, 3.0119575129581238]
[0.3823108085326076, 0.38695221105047056, 7.403751773994824]
⋮
[1.828762762194604, 1.8869592926676668, 20.93488518181765]
[0.18497925250531608, 0.18555127513243247, 16.89956790951975]
[4.7645070831256975, 4.910103364634272, 9.945119624916469]
[4.664160325341558, 4.837491459374777, 17.05587581913582]
[0.04515121987594338, 0.1515734788480168, 17.440980633994336]
[-0.01703602186720911, -0.030628053319669255, 10.625774552720417]
[-4.86176873228248, -4.9896153048975584, 13.191770390712787]
[0.1694389863247147, 0.15104001388475613, 0.014564758410169232]
[0.8690300534676783, 0.8709357247261634, 2.485098794706292]
Now let's do this with multithreading:
function tmap(f,ps) out = Vector{typeof(@SVector([1.0,0.0,0.0]))}(undef,1000) Threads.@threads for i in 1:1000 # each loop part is using a different part of the data out[i] = f(ps[i]) end out end threaded_out = tmap(p -> compute_trajectory_mean4(@SVector([1.0,0.0,0.0]),p),ps)
1000-element Vector{SVector{3, Float64}}:
[1.533821316288965, 1.4759166755885853, 19.82393323422577]
[1.912551789104003, 1.9178779249507756, 3.077751701604538]
[2.208102300830052, 2.270932656259539, 9.159452491441156]
[1.8053470721465135, 1.987767599607961, 15.348128757786332]
[3.2479403841568795, 3.4053530491931636, 6.6569065080195635]
[0.1326746410522907, 0.11287321733023505, 9.886404237821592]
[4.179931373360461, 4.234463309703314, 8.949804324284488]
[1.4146238193666851, 1.42124402080363, 3.6407841055232795]
[-0.30013594952125694, -0.3473918853474649, 3.0119575129581238]
[0.3823108085326076, 0.38695221105047056, 7.403751773994824]
⋮
[1.828762762194604, 1.8869592926676668, 20.93488518181765]
[-4.212139358561054, -4.307093399451259, 10.72812907749872]
[1.2973636714664967, 1.2852294592239, 13.55296558474145]
[0.8785958898215024, 0.632036261231246, 5.26687294635823]
[0.031854933066135016, 0.052706962373940854, 17.419298175312463]
[-0.01703602186720911, -0.030628053319669255, 10.625774552720417]
[-4.9125273155280835, -5.134240542987785, 13.148815883102877]
[0.2982736305272368, 0.26234114447166934, 2.2269693194365416]
[0.8836619370801961, 0.9256234629731426, 2.4912783676365535]
Let's check the output:
serial_out - threaded_out
1000-element Vector{SVector{3, Float64}}:
[-1.8489480054912801, -1.7804305635511581, -4.68802275667448]
[0.26540335282781213, 0.3227324905838247, -0.7966417534987946]
[-2.386267649592266, -2.450087581019265, 4.135705671625091]
[0.6285432198682268, 0.4553226755081812, -12.238239996916231]
[0.0, 0.0, 0.0]
[0.0013487036523223972, 0.0047797828359768535, 0.00024207428910649753]
[-7.638583351227403, -7.776838906604957, 0.2426336419773456]
[-0.009560443757068882, -0.013644431924056954, -0.1788550135561282]
[0.0, 0.0, 0.0]
[0.0, 0.0, 0.0]
⋮
[0.0, 0.0, 0.0]
[4.397118611066371, 4.492644674583691, 6.17143883202103]
[3.467143411659201, 3.6248739054103725, -3.6078459598249815]
[3.7855644355200555, 4.2054551981435315, 11.78900287277759]
[0.013296286809808364, 0.09886651647407596, 0.02168245868187313]
[0.0, 0.0, 0.0]
[0.050758583245603894, 0.1446252380902262, 0.0429545076099096]
[-0.1288346442025221, -0.11130113058691321, -2.2124045610263723]
[-0.014631883612517882, -0.054687738246979145, -0.00617957293026139]
Oh no, we don't get the same answer! What happened?
The answer is the caching. Every single thread is using _u_cache as the cache, and so while one is writing into it the other is reading out of it, and thus is getting the value written to it from the wrong cache!
To fix this, what we need is a different heap per thread:
const _u_cache_threads = [Vector{typeof(@SVector([1.0,0.0,0.0]))}(undef,1000) for i in 1:Threads.nthreads()] function compute_trajectory_mean5(u0,p) # u is automatically captured solve_system_save!(_u_cache_threads[Threads.threadid()],lorenz,u0,p,1000); mean(_u_cache_threads[Threads.threadid()]) end @btime compute_trajectory_mean5(@SVector([1.0,0.0,0.0]),p)
5.700 μs (1 allocation: 32 bytes)
3-element SVector{3, Float64} with indices SOneTo(3):
-0.31149962346484683
-0.3097490174897651
26.024603558583014
serial_out = map(p -> compute_trajectory_mean5(@SVector([1.0,0.0,0.0]),p),ps) threaded_out = tmap(p -> compute_trajectory_mean5(@SVector([1.0,0.0,0.0]),p),ps) serial_out - threaded_out
ERROR: TaskFailedException
nested task error: BoundsError: attempt to access 4-element Vector{Vector{SVector{3, Float64}}} at index [5]
Stacktrace:
[1] throw_boundserror(A::Vector{Vector{SVector{3, Float64}}}, I::Tuple{Int64})
@ Base ./essentials.jl:15
[2] getindex
@ ./essentials.jl:919 [inlined]
[3] compute_trajectory_mean5
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:5 [inlined]
[4] #74
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:3 [inlined]
[5] macro expansion
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:6 [inlined]
[6] (::var"#tmap##0#tmap##1"{var"#tmap##2#tmap##3"{var"#74#75", Vector{NTuple{4, Float64}}, Vector{SVector{3, Float64}}, UnitRange{Int64}}})(tid::Int64; onethread::Bool)
@ Main ./threadingconstructs.jl:276
[7] #tmap##0
@ ./threadingconstructs.jl:243 [inlined]
[8] (::Base.Threads.var"#threading_run##0#threading_run##1"{var"#tmap##0#tmap##1"{var"#tmap##2#tmap##3"{var"#74#75", Vector{NTuple{4, Float64}}, Vector{SVector{3, Float64}}, UnitRange{Int64}}}, Int64})()
@ Base.Threads ./threadingconstructs.jl:177
@btime serial_out = map(p -> compute_trajectory_mean5(@SVector([1.0,0.0,0.0]),p),ps)
5.681 ms (4 allocations: 23.52 KiB)
1000-element Vector{SVector{3, Float64}}:
[-0.31512668920231524, -0.3045138879625728, 15.13591047755129]
[2.177955141931815, 2.2406104155346003, 2.2811099481057435]
[-0.17816534876221382, -0.17915492475972628, 13.295158163066247]
[2.4338902920147403, 2.443090275116142, 3.1098887608701]
[3.2479403841568795, 3.4053530491931636, 6.6569065080195635]
[0.1340233447046131, 0.1176530001662119, 9.886646312110699]
[-3.4586519778669427, -3.5423755969016426, 9.192437966261833]
[1.4050633756096162, 1.4075995888795731, 3.4619290919671513]
[-0.30013594952125694, -0.3473918853474649, 3.0119575129581238]
[0.3823108085326076, 0.38695221105047056, 7.403751773994824]
⋮
[1.828762762194604, 1.8869592926676668, 20.93488518181765]
[0.18497925250531608, 0.18555127513243247, 16.89956790951975]
[4.7645070831256975, 4.910103364634272, 9.945119624916469]
[4.664160325341558, 4.837491459374777, 17.05587581913582]
[0.04515121987594338, 0.1515734788480168, 17.440980633994336]
[-0.01703602186720911, -0.030628053319669255, 10.625774552720417]
[-4.86176873228248, -4.9896153048975584, 13.191770390712787]
[0.1694389863247147, 0.15104001388475613, 0.014564758410169232]
[0.8690300534676783, 0.8709357247261634, 2.485098794706292]
@btime threaded_out = tmap(p -> compute_trajectory_mean5(@SVector([1.0,0.0,0.0]),p),ps)
ERROR: TaskFailedException
nested task error: BoundsError: attempt to access 4-element Vector{Vector{SVector{3, Float64}}} at index [5]
Stacktrace:
[1] throw_boundserror(A::Vector{Vector{SVector{3, Float64}}}, I::Tuple{Int64})
@ Base ./essentials.jl:15
[2] getindex
@ ./essentials.jl:919 [inlined]
[3] compute_trajectory_mean5
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:5 [inlined]
[4] #80
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:2 [inlined]
[5] macro expansion
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:6 [inlined]
[6] (::var"#tmap##0#tmap##1"{var"#tmap##2#tmap##3"{var"#80#81", Vector{NTuple{4, Float64}}, Vector{SVector{3, Float64}}, UnitRange{Int64}}})(tid::Int64; onethread::Bool)
@ Main ./threadingconstructs.jl:276
[7] #tmap##0
@ ./threadingconstructs.jl:243 [inlined]
[8] (::Base.Threads.var"#threading_run##0#threading_run##1"{var"#tmap##0#tmap##1"{var"#tmap##2#tmap##3"{var"#80#81", Vector{NTuple{4, Float64}}, Vector{SVector{3, Float64}}, UnitRange{Int64}}}, Int64})()
@ Base.Threads ./threadingconstructs.jl:177
Hierarchical Task-Based Multithreading and Dynamic Scheduling
The major change in Julia v1.3 is that Julia's Tasks, which are traditionally its green threads interface, are now the basis of its multithreading infrastructure. This means that all independent threads are parallelized, and a new interface for multithreading will exist that works by spawning threads.
This implementation follows Go's goroutines and the classic multithreading interface of Cilk. There is a Julia-level scheduler that handles the multithreading to put different tasks on different vCPU threads. A benefit from this is hierarchical multithreading. Since Julia's tasks can spawn tasks, what can happen is a task can create tasks which create tasks which etc. In Julia (/Go/Cilk), this is then seen as a single pool of tasks which it can schedule, and thus it will still make sure only N are running at a time (as opposed to the naive implementation where the total number of running threads is equal then multiplied). This is essential for numerical performance because running multiple compute threads on a single CPU thread requires constant context switching between the threads, which will slow down the computations.
To directly use the task-based interface, simply use Threads.@spawn to spawn new tasks. For example:
function tmap2(f,ps) tasks = [Threads.@spawn f(ps[i]) for i in 1:1000] out = [fetch(t) for t in tasks] end threaded_out = tmap2(p -> compute_trajectory_mean5(@SVector([1.0,0.0,0.0]),p),ps)
ERROR: TaskFailedException
nested task error: BoundsError: attempt to access 4-element Vector{Vector{SVector{3, Float64}}} at index [5]
Stacktrace:
[1] throw_boundserror(A::Vector{Vector{SVector{3, Float64}}}, I::Tuple{Int64})
@ Base ./essentials.jl:15
[2] getindex
@ ./essentials.jl:919 [inlined]
[3] compute_trajectory_mean5
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:5 [inlined]
[4] #86
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:6 [inlined]
[5] (::var"#tmap2##2#tmap2##3"{Int64, var"#86#87", Vector{NTuple{4, Float64}}})()
@ Main ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:3
However, if we check the timing we see:
@btime tmap2(p -> compute_trajectory_mean5(@SVector([1.0,0.0,0.0]),p),ps)
ERROR: TaskFailedException
nested task error: BoundsError: attempt to access 4-element Vector{Vector{SVector{3, Float64}}} at index [5]
Stacktrace:
[1] throw_boundserror(A::Vector{Vector{SVector{3, Float64}}}, I::Tuple{Int64})
@ Base ./essentials.jl:15
[2] getindex
@ ./essentials.jl:919 [inlined]
[3] compute_trajectory_mean5
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:5 [inlined]
[4] #89
@ ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:2 [inlined]
[5] (::var"#tmap2##2#tmap2##3"{Int64, var"#89#90", Vector{NTuple{4, Float64}}})()
@ Main ~/work/SciMLBook/SciMLBook/_weave/lecture05/parallelism_overview.jmd:3
Threads.@threads is built on the same multithreading infrastructure, so why is this so much slower? The reason is because Threads.@threads employs static scheduling while Threads.@spawn is using dynamic scheduling. Dynamic scheduling is the model of allowing the runtime to determine the ordering and scheduling of processes, i.e. what tasks will run run where and when. Julia's task-based multithreading system has a thread scheduler which will automatically do this for you in the background, but because this is done at runtime it will have overhead. Static scheduling is the model of pre-determining where and when tasks will run, instead of allowing this to be determined at runtime. Threads.@threads is "quasi-static" in the sense that it cuts the loop so that it spawns only as many tasks as there are threads, essentially assigning one thread for even chunks of the input data.
Does this lack of runtime overhead mean that static scheduling is "better"? No, it simply has trade-offs. Static scheduling assumes that the runtime of each block is the same. For this specific case where there are fixed number of loop iterations for the dynamical systems, we know that every compute_trajectory_mean5 costs exactly the same, and thus this will be more efficient. However, There are many cases where this might not be efficient. For example:
function sleepmap_static() out = Vector{Int}(undef,24) Threads.@threads for i in 1:24 sleep(i/10) out[i] = i end out end isleep(i) = (sleep(i/10);i) function sleepmap_spawn() tasks = [Threads.@spawn(isleep(i)) for i in 1:24] out = [fetch(t) for t in tasks] end @btime sleepmap_static() @btime sleepmap_spawn()
12.913 s (97 allocations: 4.69 KiB)
2.401 s (198 allocations: 11.03 KiB)
24-element Vector{Int64}:
1
2
3
4
5
6
7
8
9
10
⋮
16
17
18
19
20
21
22
23
24
The reason why this occurs is because of how the static scheduling had chunked my calculation. On my computer:
Threads.nthreads()
4
This means that there are 6 tasks that are created by Threads.@threads. The first takes:
sum(i/10 for i in 1:4)
1.0
1 second, while the next group takes longer, then the next, etc. while the last takes:
sum(i/10 for i in 21:24)
9.0
9 seconds (which is precisely the result!). Thus by unevenly distributing the runtime, we run as fast as the slowest thread. However, dynamic scheduling allows new tasks to immediately run when another is finished, meaning that the in that case the shorter tasks tend to be piled together, causing a faster execution. Thus whether dynamic or static scheduling is beneficial is dependent on the problem and the implementation of the static schedule.
Possible Project
Note that this can extend to external library calls as well. FFTW.jl recently gained support for this. A possible final project would be to do a similar change to OpenBLAS.
A Teaser for Alternative Parallelism Models
Simplest Parallel Code
A = rand(10000,10000) B = rand(10000,10000) A*B
10000×10000 Matrix{Float64}:
2483.0 2524.09 2502.32 2493.1 … 2495.78 2507.9 2501.9 2517.92
2481.22 2523.85 2526.42 2496.12 2503.86 2504.39 2498.61 2537.81
2483.16 2497.43 2490.54 2479.09 2483.09 2481.76 2461.58 2506.69
2481.41 2499.74 2496.29 2454.0 2493.81 2501.73 2483.06 2511.74
2474.15 2509.75 2518.25 2480.79 2495.27 2490.45 2491.57 2538.07
2502.68 2536.68 2540.84 2490.1 … 2523.88 2523.15 2493.41 2539.18
2490.25 2538.53 2523.68 2489.91 2498.62 2494.83 2484.38 2537.83
2483.29 2528.74 2519.11 2502.02 2495.38 2521.91 2497.48 2536.86
2482.13 2507.43 2517.95 2482.03 2495.3 2497.05 2487.78 2534.55
2511.43 2549.8 2530.7 2512.19 2533.42 2540.56 2521.24 2554.38
⋮ ⋱
2488.13 2538.05 2525.95 2508.35 2513.74 2519.0 2495.49 2540.19
2450.72 2486.42 2490.67 2450.77 2466.46 2470.5 2456.1 2504.24
2466.17 2501.04 2492.61 2469.79 2481.83 2479.81 2472.48 2507.89
2467.62 2500.1 2495.15 2468.59 2495.22 2497.57 2464.95 2510.97
2497.05 2530.35 2523.8 2480.5 … 2513.34 2524.35 2490.84 2545.43
2485.48 2534.57 2518.74 2497.09 2508.79 2533.14 2484.13 2533.7
2479.65 2516.02 2515.81 2462.85 2495.45 2514.05 2483.85 2519.34
2492.23 2535.07 2524.19 2484.18 2513.97 2521.94 2517.28 2530.01
2474.27 2518.96 2500.89 2487.18 2495.14 2488.12 2481.61 2516.04
If you are using a computer that has N cores, then this will use N cores. Try it and look at your resource usage!
Array-Based Parallelism
The simplest form of parallelism is array-based parallelism. The idea is that you use some construction of an array whose operations are already designed to be parallel under the hood. In Julia, some examples of this are:
DistributedArrays (Distributed Computing)
Elemental
MPIArrays
CuArrays (GPUs)
This is not a Julia specific idea either.
BLAS and Standard Libraries
The basic linear algebra calls are all handled by a set of libraries which follow the same interface known as BLAS (Basic Linear Algebra Subroutines). It's divided into 3 portions:
BLAS1: Element-wise operations (O(n))
BLAS2: Matrix-vector operations (O(n^2))
BLAS3: Matrix-matrix operations (O(n^3))
BLAS implementations are highly optimized, like OpenBLAS and Intel MKL, so every numerical language and library essentially uses similar underlying BLAS implementations. Extensions to these, known as LAPACK, include operations like factorizations, and are included in these standard libraries. These are all multithreaded. The reason why this is a location to target is because the operation count is high enough that parallelism can be made efficient even when only targeting this level: a matrix multiplication can take on the order of seconds, minutes, hours, or even days, and these are all highly parallel operations. This means you can get away with a bunch just by parallelizing at this level, which happens to be a bottleneck for a lot scientific computing codes.
This is also commonly the level at which GPU computing occurs in machine learning libraries for reasons which we will explain later.
MPI
Well, this is a big topic and we'll address this one later!
Conclusion
The easiest forms of parallelism are:
Embarrassingly parallel
Array-level parallelism (built into linear algebra)
Exploit these when possible.