Lecture Overview
- Lecture 1: Introduction and Syllabus
- Lecture 2: Optimizing Serial Code
- Lecture 3: Introduction to Scientific Machine Learning Through Physics-Informed Neural Networks
- Lecture 4: Introduction to Discrete Dynamical Systems
- Lecture 5: Array-Based Parallelism, Embarrassingly Parallel Problems, and Data-Parallelism: The Basics of Single Node Parallel Computing
- Lecture 6: Styles of Parallelism
- Lecture 7: Ordinary Differential Equations: Applications and Discretizations
- Lecture 8: Forward-Mode Automatic Differentiation
- Lecture 9: Solving Stiff Ordinary Differential Equations
- Lecture 10: Basic Parameter Estimation, Reverse-Mode AD, and Inverse Problems
- Lecture 11: Differentiable Programming and Neural Differential Equations
- Lecture 12: SciML in Practice
- Lecture 13: GPU Computing
- Lecture 14: Partial Differential Equations and Convolutional Neural Networks
- Lecture 15: More Algorithms which Connect Differential Equations and Machine Learning
- Lecture 16: Probabilistic Programming
- Lecture 17: Global Sensitivity Analysis
- Lecture 18: Code Profiling and Optimization
- Lecture 19: Uncertainty Programming and Generalized Uncertainty Quantification
- Final Project
Lecture 1: Introduction and Syllabus
Lecture 1.0: Introduction
Lecture and Notes
This is to make sure we're all on the same page. It goes over the syllabus and what will be expected of you throughout the course. If you have not joined the Slack, please use the link from the introduction email (or email me if you need the link!).
Lecture 1.1: Getting Started with Julia
Lecture and Notes
Optional Extra Resources
If you are not comfortable with Julia yet, here's a few resources as sort of a "crash course" to get you up an running:
Some deeper materials:
Steven Johnson will be running a Julia workshop on 9/8/2020 for people who are interested. More details TBA.
Lecture 2: Optimizing Serial Code
Lecture and Notes
Optimizing Serial Code in Julia 1: Memory Models, Mutation, and Vectorization (Lecture)
Optimizing Serial Code in Julia 2: Type inference, function specialization, and dispatch (Lecture)
Optional Extra Resources
Type-Dispatch Design: Post Object-Oriented Programming for Julia
When FFI Function Calls Beat Native C (How JIT compilation allows C-calls to be faster than C)
Before we start to parallelize code, build huge models, and automatically learn physics, we need to make sure our code is "good". How do you know you're writing "good" code? That's what this lecture seeks to answer. In this lecture we'll go through the techniques for writing good serial code and checking that your code is efficient.
Lecture 3: Introduction to Scientific Machine Learning Through Physics-Informed Neural Networks
Introduction to Scientific Machine Learning 1: Deep Learning as Function Approximation (Lecture)
Introduction to Scientific Machine Learning 2: Physics-Informed Neural Networks (Lecture)
Introduction to Scientific Machine Learning through Physics-Informed Neural Networks (Notes)
Optional Extra Resources
Universal Differential Equations for Scientific Machine Learning
JuliaCon 2020 | Keynote: Scientific Machine Learning | Prof Karen Willcox (High Level)
DOE Workshop Report on Basic Research Needs for Scientific Machine Learning
Now let's take our first stab at the application: scientific machine learning. What is scientific machine learning? We will define the field by looking at a few approaches people are taking and what kinds of problems are being solved using scientific machine learning. The field of scientific machine learning and its span across computational science to applications in climate modeling and aerospace will be introduced. The methodologies that will be studied, in their various names, will be introduced, and the general formula that is arising in the discipline will be laid out: a mixture of scientific simulation tools like differential equations with machine learning primitives like neural networks, tied together through differentiable programming to achieve results that were previously not possible. After doing a survey, we while dive straight into developing a physics-informed neural network solver which solves an ordinary differential equation.
Lecture 4: Introduction to Discrete Dynamical Systems
How Loops Work 1: An Introduction to the Theory of Discrete Dynamical Systems (Lecture)
How Loops Work 2: Computationally-Efficient Discrete Dynamics (Lecture)
How Loops Work, An Introduction to Discrete Dynamics (Notes)
Optional Extra Resources
Now that the stage is set, we see that to go deeper we will need a good grasp on how both discrete and continuous dynamical systems work. We will start by developing the basics of our scientific simulators: differential and difference equations. A quick overview of geometric results in the study of differential and difference equations will set the stage for understanding nonlinear dynamics, which we will quickly turn to numerical methods to visualize. Even if there is not analytical solution to the dynamical system, overarching behavior such as convergence to zero can be determined through asymptotic means and linearization. We will see later that these same techniques for the basis for the analysis of numerical methods for differential equations, such as the Runge-Kutta and Adams-Bashforth methods.
Since the discretization of differential equations is indeed a discrete dynamical system, we will use this as a case study to see how serial scalar-heavy codes should be optimized. SIMD, in-place operations, broadcasting, heap allocations, and static arrays will be used to get fast codes for dynamical system simulation. These simulations will then be used to reveal some intriguing properties of dynamical systems which will be further explored through the rest of the course.
Lecture 5: Array-Based Parallelism, Embarrassingly Parallel Problems, and Data-Parallelism: The Basics of Single Node Parallel Computing
Optional Extra Resources
{kind=link}
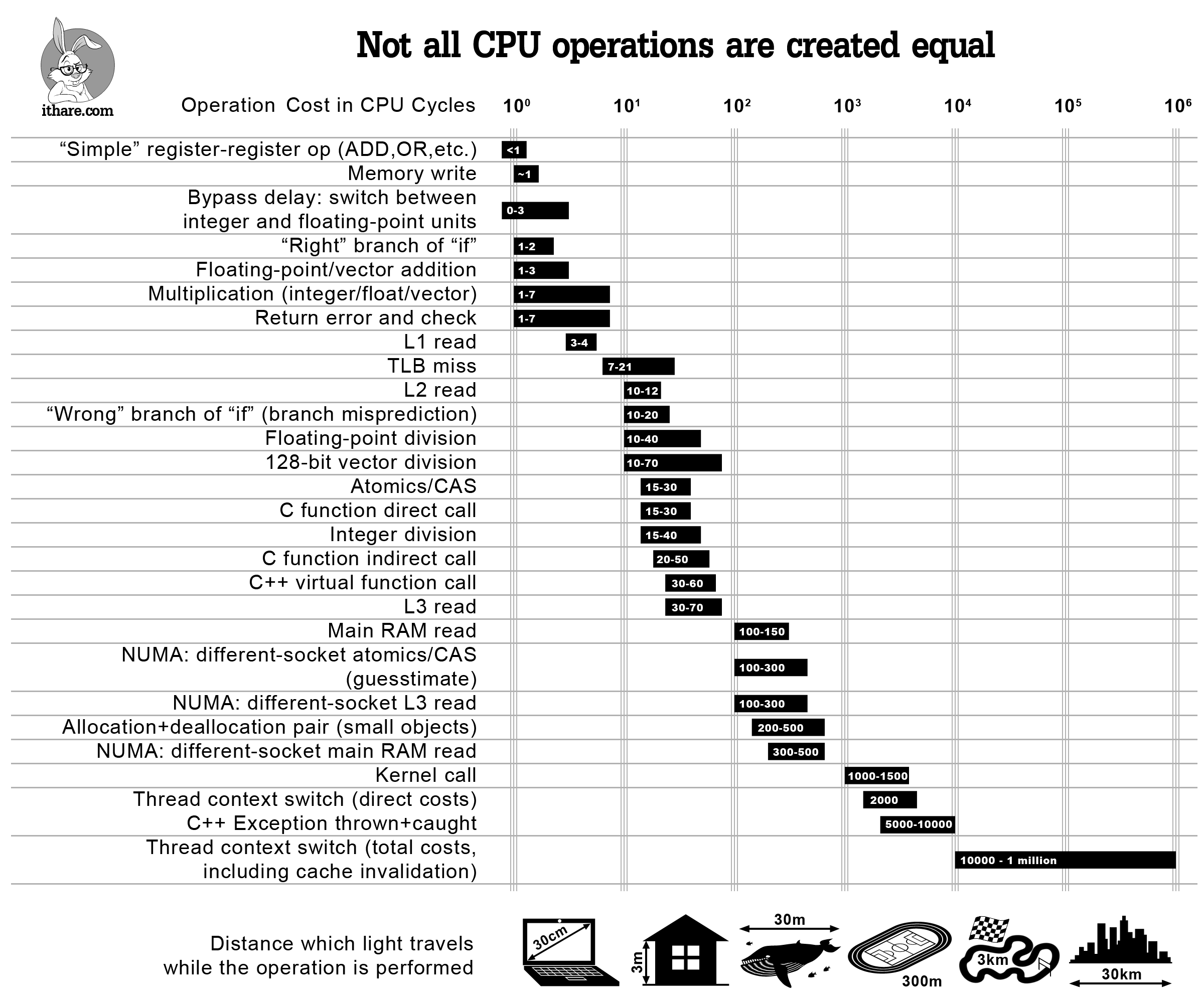
Now that we have a concrete problem, let's start investigating ways to parallelize its solution. We will first see that many systems have an almost automatic way of parallelizing through array operations, which we will call array-based parallelism. The ability to easily parallelize large blocked linear algebra will be discussed, along with libraries like OpenBLAS, Intel MKL, CuBLAS (GPU parallelism) and Elemental.jl. This gives a form of Within-Method Parallelism which we can use to optimize specific algorithms which utilize linearity. Another form of parallelism is to parallelize over the inputs. We will describe how this is a form of data parallelism, and use this as a framework to introduce shared memory and distributed parallelism. The interactions between these parallelization methods and application considerations will be discussed.
Lecture 6: Styles of Parallelism
Here we continue down the line of describing methods of parallelism by giving a high level overview of the types of parallelism. SIMD and multithreading are reviewed as the basic forms of parallelism where message passing is not a concern. Then accelerators, such as GPUs and TPUs are introduced. Moving further, distributed parallel computing and its models are showcased. What we will see is that what kind of parallelism we are doing actually is not the main determiner as to how we need to think about parallelism. Instead, the determining factor is the parallel programming model, where just a handful of models, like task-based parallelism or SPMD models, are seen across all of the different hardware abstractions.
Lecture 7: Ordinary Differential Equations: Applications and Discretizations
Ordinary Differential Equations 1: Applications and Solution Characteristics (Lecture)
Ordinary Differential Equations 2: Discretizations and Stability (Lecture)
Ordinary Differential Equations: Applications and Discretizations (Notes)
In this lecture we will describe ordinary differential equations, where they arise in scientific contexts, and how they are solved. We will see that understanding the properties of the numerical methods requires understanding the dynamics of the discrete system generated from the approximation to the continuous system, and thus stability of a numerical method is directly tied to the stability properties of the dynamics. This gives the idea of stiffness, which is a larger computational idea about ill-conditioned systems.
Lecture 8: Forward-Mode Automatic Differentiation
Forward-Mode Automatic Differentiation (AD) via High Dimensional Algebras (Lecture)
Forward-Mode Automatic Differentiation (AD) via High Dimensional Algebras (Notes)
As we will soon see, the ability to calculate derivatives underpins a lot of problems in both scientific computing and machine learning. We will specifically see it show up in later lectures on solving implicit equations f(x)=0 for stiff ordinary differential equation solvers, and in fitting neural networks. The common high performance way that this is done is called automatic differentiation. This lecture introduces the methods of forward and reverse mode automatic differentiation to setup future studies uses of the technique.
Lecture 9: Solving Stiff Ordinary Differential Equations
Lecture Notes
Additional Readings on Convergence of Newton's Method
Solving stiff ordinary differential equations, especially those which arise from partial differential equations, are the common bottleneck of scientific computing. The largest-scale scientific computing models are generally using heavy compute power in order to tackle some implicitly timestepped PDE solve! Thus we will take a deep dive into how the different methods which are combined to create a stiff ordinary differential equation solver, looking at different aspects of Jacobian computations and linear solving and the effects that they have.
Lecture 10: Basic Parameter Estimation, Reverse-Mode AD, and Inverse Problems
Basic Parameter Estimation, Reverse-Mode AD, and Inverse Problems (Lecture)
Basic Parameter Estimation, Reverse-Mode AD, and Inverse Problems (Notes)
Now that we have models, how do you fit the models to data? This lecture goes through the basic shooting method for parameter estimation, showcases how it's equivalent to training neural networks, and gives an in-depth discussion of how reverse-mode automatic differentiation is utilized in the training process for the efficient calculation of gradients.
Lecture 11: Differentiable Programming and Neural Differential Equations
Differentiable Programming Part 1: Reverse-Mode AD Implementation (Lecture)
Differentiable Programming and Neural Differential Equations (Notes)
Additional Readings on AD Implementations
Given the efficiency of reverse-mode automatic differentiation, we want to see how far we can push this idea. How could one implement reverse-mode AD without computational graphs, and include problems like nonlinear solving and ordinary differential equations? Are there methods other than shooting methods that can be utilized for parameter fitting? This lecture will explore where reverse-mode AD intersects with scientific modeling, and where machine learning begins to enter scientific computing.
Lecture 12: SciML in Practice
Lecture 12.1: MPI for Distributed Computing
Guest Lecturer: Lauren E. Milechin, MIT Lincoln Lab and the MIT Supercloud Guest Writer: Jeremy Kepner, MIT Lincoln Lab and the MIT Supercloud
In this lecture we went over the basics of MPI (Message Passing Interface) for distributed computing and examples on how to use MPI.jl to write parallel programs that work efficiently over multiple computers (or "compute nodes"). The MPI programming model and the job scripts required for using MPI on the MIT Supercloud HPC were demonstrated.
Lecture 12.2: Mathematics of Machine Learning and High Performance Computing
Guest Lecturer: Jeremy Kepner, MIT Lincoln Lab and the MIT Supercloud
Mathematical Foundations of the GraphBLAS and Big Data (Lecture)
Performance Metrics and Software Architecture (Book Chapter)
In this lecture we went over the mathematics behind big data, machine learning, and high performance computing. Pieces like Amdahl's law for describing maximal parallel compute efficiency were described and demonstrated to showcase some hard ceiling on the capabilities of parallel computing, and these laws were described in the context of big data computations in order to assess the viability of distributed computing within that domain's context.
Lecture 13: GPU Computing
Guest Lecturer: Valentin Churavy, MIT Julia Lab
In this lecture we take a deeper dive into the architectural differences of GPUs and how that changes the parallel computing mindset that's required to arrive at efficient code. Valentin walks through the compilation process and how the resulting behaviors are due to core trade-offs in GPU-based programming and direct compilation for such hardware.
Lecture 14: Partial Differential Equations and Convolutional Neural Networks
Additional Readings
In this lecture we will continue to relate the methods of machine learning to those in scientific computing by looking at the relationship between convolutional neural networks and partial differential equations. It turns out they are more than just similar: the two are both stencil computations on spatial data!
Lecture 15: More Algorithms which Connect Differential Equations and Machine Learning
Mixing Differential Equations and Neural Networks for Physics-Informed Learning (Lecture)
Mixing Differential Equations and Neural Networks for Physics-Informed Learning (Notes)
Neural ordinary differential equations and physics-informed neural networks are only the tip of the iceberg. In this lecture we will look into other algorithms which are utilizing the connection between neural networks and machine learning. We will generalize to augmented neural ordinary differential equations and universal differential equations with DiffEqFlux.jl, which now allows for stiff equations, stochasticity, delays, constraint equations, event handling, etc. to all take place in a neural differential equation format. Then we will dig into the methods for solving high dimensional partial differential equations through transformations to backwards stochastic differential equations (BSDEs), and the applications to mathematical finance through Black-Scholes along with stochastic optimal control through Hamilton-Jacobi-Bellman equations. We then look into alternative training techniques using reservoir computing, such as continuous-time echo state networks, which alleviate some of the gradient issues associated with training neural networks on stiff and chaotic dynamical systems. We showcase a few of the methods which are being used to automatically discover equations in their symbolic form such as SINDy. To end it, we look into methods for accelerating differential equation solving through neural surrogate models, and uncover the true idea of what's going on, along with understanding when these applications can be used effectively.
Lecture 16: Probabilistic Programming
All of our previous discussions lived in a deterministic world. Not this one. Here we turn to a probabilistic view and allow programs to have random variables. Forward simulation of a random program is seen to be simple through Monte Carlo sampling. However, parameter estimation is now much more involved, since in this case we need to estimate not just values but probability distributions. It turns out that Bayes' rule gives a framework for performing such estimations. We see that classical parameter estimation falls out as a maximization of probability with the "simplest" form of distributions, and thus this gives a nice generalization even to standard parameter estimation and justifies the use of L2 loss functions and regularization (as a perturbation by a prior). Next, we turn to estimating the distributions, which we see is possible for small problems using Metropolis Hastings, but for larger problems we develop Hamiltonian Monte Carlo. It turns out that Hamiltonian Monte Carlo has strong ties to both ODEs and differentiable programming: it is defined as solving ODEs which arise from a Hamiltonian, and derivatives of the likelihood are required, which is essentially the same idea as derivatives of cost functions! We then describe an alternative approach: Automatic Differentiation Variational Inference (ADVI), which once again is using the tools of differentiable programming to estimate distributions of probabilistic programs.
Lecture 17: Global Sensitivity Analysis
Our previous analysis of sensitivities was all local. What does it mean to example the sensitivities of a model globally? It turns out the probabilistic programming viewpoint gives us a solid way of describing how we expect values to be changing over larger sets of parameters via the random variables that describe the program's inputs. This means we can decompose the output variance into indices which can be calculated via various quadrature approximations which then give a tractable measurement to "variable x has no effect on the mean solution".
Lecture 18: Code Profiling and Optimization
How do you put everything together in this course? Let's take a look at a PDE solver code given in a method of lines form. In this lecture I walk through the code and demonstrate how to serial optimize it, and showcase the interaction between variable caching and automatic differentiation.
Lecture 19: Uncertainty Programming and Generalized Uncertainty Quantification
We end the course by taking a look at another mathematical topic to see whether it can be addressed in a similar manner: uncertainty quantification (UQ). There are ways which it can be handled similar to automatic differentiation. Measurements.jl gives a forward-propagation approach, somewhat like ForwardDiff's dual numbers, through a number type which is representative of normal distributions and pushes these values through a program. This has many advantages, since it allows for uncertainty quantification without sampling, but turns the number types into a value that is heap allocated. Other approaches are investigated, like interval arithmetic which is rigorous but limited in scope. But on the entirely other end, a non-general method for ODEs is shown which utilizes the trajectory structure of the differential equation solution and doesn't give the blow up that the other methods see. This showcases that uses higher level information can be helpful in UQ, and less local approaches may be necessary. We end by showcasing the Koopman operator as the adjoint of the pushforward of the uncertainty measure, and as an adjoint method it can give accelerated computations of uncertainty against cost functions.
Final Project
The final project is a 10-20 page paper using the style template from the SIAM Journal on Numerical Analysis (or similar). The final project must include code for a high performance (or parallelized) implementation of the algorithm in a form that is usable by others. A thorough performance analysis is expected. Model your paper on academic review articles (e.g. read SIAM Review and similar journals for examples).
One possibility is to review an interesting algorithm not covered in the course and develop a high performance implementation. Some examples include:
High performance PDE solvers for specific PDEs like Navier-Stokes
Common high performance algorithms (Ex: Jacobian-Free Newton Krylov for PDEs)
Recreation of a parameter sensitivity study in a field like biology, pharmacology, or climate science
Parallelized stencil calculations
Distributed linear algebra kernels
Parallel implementations of statistical libraries, such as survival statistics or linear models for big data. Here's one example parallel library) and a second example.
Parallelization of data analysis methods
Type-generic implementations of sparse linear algebra methods
A fast regex library
Math library primitives (exp, log, etc.)
Another possibility is to work on state-of-the-art performance engineering. This would be implementing a new auto-parallelization or performance enhancement. For these types of projects, implementing an application for benchmarking is not required, and one can instead benchmark the effects on already existing code to find cases where it is beneficial (or leads to performance regressions). Possible examples are:
Create a system for automatic multithreaded parallelism of array operations and see what kinds of packages end up more efficient
Setup BLAS with a PARTR backend and investigate the downstream effects on multithreaded code like an existing PDE solver
Investigate the effects of work-stealing in multithreaded loops
Fast parallelized type-generic FFT. Starter code by Steven Johnson (creator of FFTW) and Yingbo Ma can be found here
Type-generic BLAS. Starter code can be found here
Implementation of parallelized map-reduce methods. For example,
pmapreduceextension topmapthat adds a parallelized reduction, or a fast GPU-based map-reduce.Investigating auto-compilation of full package codes to GPUs using tools like CUDAnative and/or GPUifyLoops.
Investigating alternative implementations of databases and dataframes. NamedTuple backends of DataFrames, alternative type-stable DataFrames, defaults for CSV reading and other large-table formats like JuliaDB.
Additionally, Scientific Machine Learning is a wide open field with lots of low hanging fruit. Instead of a review, a suitable research project can be used for chosen for the final project. Possibilities include:
Acceleration methods for adjoints of differential equations
Improved methods for Physics-Informed Neural Networks
New applications of neural differential equations
Parallelized implicit ODE solvers for large ODE systems
GPU-parallelized ODE/SDE solvers for small systems
Final project topics must be declared by October 30th with a 1 page extended abstract.
© Chris Rackauckas. Last modified: June 29, 2026.
Built with Franklin.jl and the Julia programming language.