PDEs, Convolutions, and the Mathematics of Locality
Chris Rackauckas
December 4th, 2020
Youtube Video
At this point we have identified how the worlds of machine learning and scientific computing collide by looking at the parameter estimation problem. Training neural networks is parameter estimation of a function f where f is a neural network. Backpropagation of a neural network is simply the adjoint problem for f, and it falls under the class of methods used in reverse-mode automatic differentiation. But this story also extends to structure. Recurrent neural networks are the Euler discretization of a continuous recurrent neural network, also known as a neural ordinary differential equation.
Given all of these relations, our next focus will be on the other class of commonly used neural networks: the convolutional neural network (CNN). It turns out that in this case there is also a clear analogue to convolutional neural networks in traditional scientific computing, and this is seen in discretizations of partial differential equations. To see this, we will first describe the convolution operation that is central to the CNN and see how this object naturally arises in numerical partial differential equations.
Convolutional Neural Networks
The purpose of a convolutional neural network is to be a network which makes use of the spatial structure of an image. An image is a 3-dimensional object: width, height, and 3 color channels. The convolutional operations keeps this structure intact and acts against this object is a 3-tensor. A convolutional layer is a function that applies a stencil to each point. This is illustrated by the following animation:
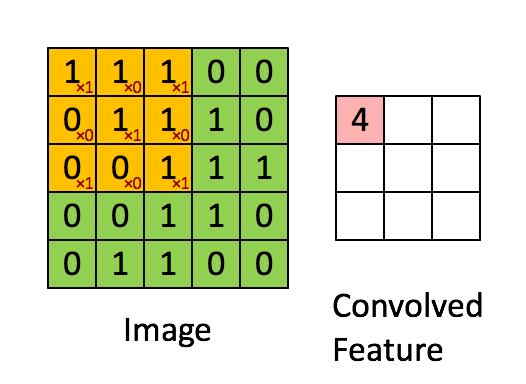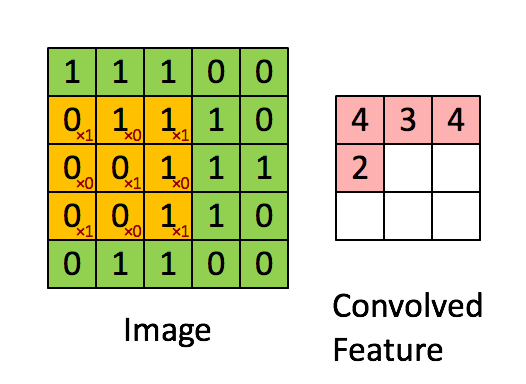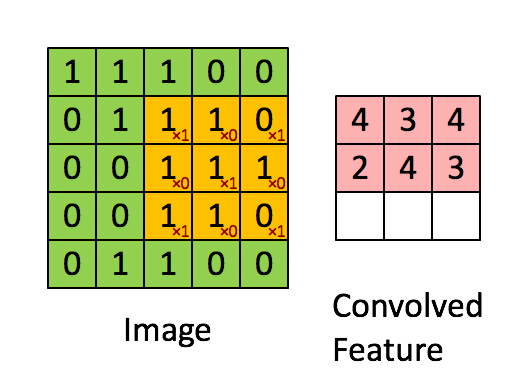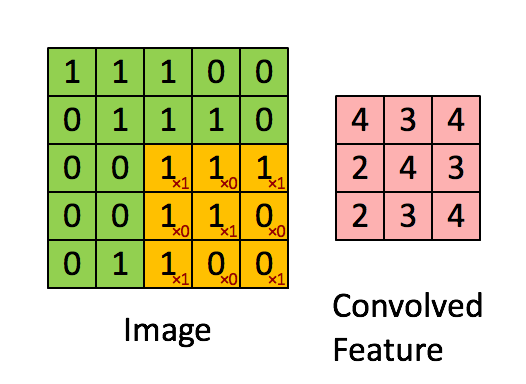
This is the 2D stencil:
1 0 1
0 1 0
1 0 1which is then applied to the matrix at each inner point to go from an NxNx3 matrix to an (N-2)x(N-2)x3 matrix.
Another operation used with convolutions is the pooling layer. For example, the maxpool layer is stencil which takes the maximum of the the value and its neighbor, and the meanpool takes the mean over the nearby values, i.e. it is equivalent to the stencil:
1/9 1/9 1/9
1/9 1/9 1/9
1/9 1/9 1/9A convolutional neural network is then composed of layers of this form. We can express this mathematically by letting $conv(x;S)$ as the convolution of $x$ given a stencil $S$. If we let $dense(x;W,b,σ) = σ(W*x + b)$ as a layer from a standard neural network, then deep convolutional neural networks are of forms like:
\[ CNN(x) = dense(conv(maxpool(conv(x)))) \]
which can be expressed in Lux.jl syntax as:
m = Chain( Conv((2,2), 1=>16, relu), x -> maxpool(x, (2,2)), Conv((2,2), 16=>8, relu), x -> maxpool(x, (2,2)), x -> reshape(x, :, size(x, 4)), Dense(288, 10), softmax) |> gpu
Discretizations of Partial Differential Equations
Now let's investigate discretizations of partial differential equations. A canonical differential equation to start with is the Poisson equation. This is the equation:
\[ u_{xx} = f(x) \]
where here we have that subscripts correspond to partial derivatives, i.e. this syntax stands for the partial differential equation:
\[ \frac{d^2u}{dx^2} = f(x) \]
In this case, $f$ is some given data and the goal is to find the $u$ that satisfies this equation. There are two ways this is generally done:
Expand out the derivative in terms of Taylor series approximations.
Expand out $u$ in terms of some function basis.
Finite Difference Discretizations
Let's start by looking at Taylor series approximations to the derivative. In this case, we will use what's known as finite differences. The simplest finite difference approximation is known as the first order forward difference. This is commonly denoted as
\[ \delta_{+}u=\frac{u(x+\Delta x)-u(x)}{\Delta x} \]
This looks like a derivative, and we think it's a derivative as $\Delta x\rightarrow 0$, but let's show that this approximation is meaningful. Assume that $u$ is sufficiently nice. Then from a Taylor series we have that
\[ u(x+\Delta x)=u(x)+\Delta xu^{\prime}(x)+\mathcal{O}(\Delta x^{2}) \]
(here I write $\left(\Delta x\right)^{2}$ as $\Delta x^{2}$ out of convenience, note that those two terms are not necessarily the same). That term on the end is called “Big-O Notation”. What is means is that those terms are asymptotically like $\Delta x^{2}$. If $\Delta x$ is small, then $\Delta x^{2}\ll\Delta x$ and so we can think of those terms as smaller than any of the terms we show in the expansion. By simplification notice that we get
\[ \frac{u(x+\Delta x)-u(x)}{\Delta x}=u^{\prime}(x)+\mathcal{O}(\Delta x) \]
This means that $\delta_{+}$ is correct up to first order, where the $\mathcal{O}(\Delta x)$ portion that we dropped is the error. Thus $\delta_{+}$ is a first order approximation.
Notice that the same proof shows that the backwards difference,
\[ \delta_{-}u=\frac{u(x)-u(x-\Delta x)}{\Delta x} \]
is first order.
Second Order Approximations to the First Derivative
Now let's look at the following:
\[ \delta_{0}u=\frac{u(x+\Delta x)-u(x-\Delta x)}{2\Delta x}. \]
The claim is this differencing scheme is second order. To show this, we once again turn to Taylor Series. Let's do this for both terms:
\[ u(x+\Delta x) =u(x)+\Delta xu^{\prime}(x)+\frac{\Delta x^{2}}{2}u^{\prime\prime}(x)+\mathcal{O}(\Delta x^{3}) \]
\[ u(x-\Delta x) =u(x)-\Delta xu^{\prime}(x)+\frac{\Delta x^{2}}{2}u^{\prime\prime}(x)+\mathcal{O}(\Delta x^{3}) \]
Now we subtract the two:
\[ u(x+\Delta x)-u(x-\Delta x)=2\Delta xu^{\prime}(x)+\mathcal{O}(\Delta x^{3}) \]
and thus we move tems around to get
\[ \delta_{0}u=\frac{u(x+\Delta x)-u(x-\Delta x)}{2\Delta x}=u^{\prime}(x)+\mathcal{O}\left(\Delta x^{2}\right) \]
What does this improvement mean? Let's say we go from $\Delta x$ to $\frac{\Delta x}{2}$. Then while the error from the first order method is around $\frac{1}{2}$ the original error, the error from the central differencing method is $\frac{1}{4}$ the original error! When trying to get an accurate solution, this quadratic reduction can make quite a difference in the number of required points.
Second Derivative Central Difference
Now we want a second derivative approximation. Let's show the classic central difference formula for the second derivative:
\[ \delta_{0}^{2}u=\frac{u(x+\Delta x)-2u(x)+u(x-\Delta x)}{\Delta x^{2}} \]
is second order. To do so, we expand out the two terms:
\[ u(x+\Delta x) =u(x)+\Delta xu^{\prime}(x)+\frac{\Delta x^{2}}{2}u^{\prime\prime}(x)+\frac{\Delta x^{3}}{6}u^{\prime\prime\prime}(x)+\mathcal{O}\left(\Delta x^{4}\right) \]
\[ u(x-\Delta x) =u(x)-\Delta xu^{\prime}(x)+\frac{\Delta x^{2}}{2}u^{\prime\prime}(x)-\frac{\Delta x^{3}}{6}u^{\prime\prime\prime}(x)+\mathcal{O}\left(\Delta x^{4}\right) \]
and now plug it in. It's clear the $u(x)$ cancels out. The opposite signs makes $u^{\prime}(x)$ cancel out, and then the same signs and cancellation makes the $u^{\prime\prime}$ term have a coefficient of 1. But, the opposite signs makes the $u^{\prime\prime\prime}$ term cancel out. Thus when we simplify and divide by $\Delta x^{2}$ we get
\[ \frac{u(x+\Delta x)-2u(x)+u(x-\Delta x)}{\Delta x^{2}}=u^{\prime\prime}(x)+\mathcal{O}\left(\Delta x^{2}\right). \]
Finite Differencing from Polynomial Interpolation
Finite differencing can also be derived from polynomial interpolation. Draw a line between two points. What is the approximation for the first derivative?
\[ \delta_{+}u=\frac{u(x+\Delta x)-u(x)}{\Delta x} \]
Now draw a quadratic through three points. i.e., given $u_{1}$, $u_{2}$, and $u_{3}$ at $x=0$, $\Delta x$, $2\Delta x$, we want to find the interpolating polynomial
\[ g(x)=a_{1}x^{2}+a_{2}x+a_{3} \]
.
Setting $g(0)=u_{1}$, $g(\Delta x)=u_{2}$, and $g(2\Delta x)=u_{3}$, we get the following relations:
\[ u_{1} =g(0)=a_{3} \]
\[ u_{2} =g(\Delta x)=a_{1}\Delta x^{2}+a_{2}\Delta x+a_{3} \]
\[ u_{3} =g(2\Delta x)=4a_{1}\Delta x^{2}+2a_{2}\Delta x+a_{3} \]
which when we write in matrix form is:
\[ \left(\begin{array}{ccc} 0 & 0 & 1\\ \Delta x^{2} & \Delta x & 1\\ 4\Delta x^{2} & 2\Delta x & 1 \end{array}\right)\left(\begin{array}{c} a_{1}\\ a_{2}\\ a_{3} \end{array}\right)=\left(\begin{array}{c} u_{1}\\ u_{2}\\ u_{3} \end{array}\right) \]
and thus we can invert the matrix to get the a's:
\[ a_{1} =\frac{u_{3}-2u_{2}+u_{1}}{2\Delta x^{2}} \]
\[ a_{2} =\frac{-u_{3}+4u_{2}-3u_{1}}{2\Delta x} \]
\[ a_{3} =u_{1}\text{ or }g(x)=\frac{u_{3}-2u_{2}-u_{1}}{2\Delta x^{2}}x^{2}+\frac{-u_{3}+4u_{2}-3u_{1}}{2\Delta x}x+u_{1} \]
Now we can get derivative approximations from this. Notice for example that
\[ g^{\prime}(x)=\frac{u_{3}-2u_{2}+u_{1}}{\Delta x^{2}}x+\frac{-u_{3}+4u_{2}-3u_{1}}{2\Delta x} \]
Now what's the derivative at the middle point?
\[ g^{\prime}\left(\Delta x\right)=\frac{u_{3}-2u_{2}+u_{1}}{\Delta x}+\frac{-u_{3}+4u_{2}-3u_{1}}{2\Delta x}=\frac{u_{3}-u_{1}}{2\Delta x}. \]
And now check
\[ g^{\prime\prime}(\Delta x)=\frac{u_{3}-2u_{2}+u_{1}}{\Delta x^{2}} \]
which is the central derivative formula. This gives a systematic way of deriving higher order finite differencing formulas. In fact, this formulation allows one to derive finite difference formulae for non-evenly spaced grids as well! The algorithm which automatically generates stencils from the interpolating polynomial forms is the Fornberg algorithm.
Multidimensional Finite Difference Operations
Now let's look at the multidimensional Poisson equation, commonly written as:
\[ \Delta u = f(x,y) \]
where $\Delta u = u_{xx} + u_{yy}$. Using the logic of the previous sections, we can approximate the two derivatives to have:
\[ \frac{u(x+\Delta x,y)-2u(x,y)+u(x-\Delta x,y)}{\Delta x^{2}} + \frac{u(x,y+\Delta y)-2u(x,y)+u(x-x,y-\Delta y)}{\Delta y^{2}}=u^{\prime\prime}(x)+\mathcal{O}\left(\Delta x^{2}\right) + \mathcal{O}\left(\Delta y^{2}\right). \]
Notice that this is the stencil operation:
0 1 0
1 -4 1
0 1 0This means that derivative discretizations are stencil or convolutional operations.
Representation and Implementation of Stencil Operations
Stencil Operations as Sparse Matrices
Stencil operations are linear operators, i.e. $S[x+\alpha y] = S[x] + \alpha S[y]$ for any sufficiently nice stencil operation $S$ (note "sufficiently nice": there is a "stencil" operation mentioned in the convolutional neural networks section which was not linear: which operation was it?). Now we write these operators as matrices. Notice that for the vector:
\[ U=\left(\begin{array}{c} u_{1}\\ \vdots\\ u_{n} \end{array}\right), \]
we have that
\[ \delta_{+}U=\left(\begin{array}{c} u_{2}-u_{1}\\ \vdots\\ u_{n}-u_{n-1} \end{array}\right) \]
and so
\[ \delta_{+}=\left(\begin{array}{ccccc} -1 & 1\\ & -1 & 1\\ & & \ddots & \ddots\\ & & & -1 & 1 \end{array}\right) \]
We can do the same to understand the other operators. But notice something: this operator isn't square! In order for this to be square, in order to know what happens at the endpoint, we need to know the boundary conditions. I.e., an assumption on the value or derivative at $u(0)$ or $u(1)$ is required in order to get the first/last rows of the matrix!
Similarly, $\delta_{0}^{2}$ can be represented as the tridiagonal matrix of [1 -2 1], also known as the Strang matrix.
Now let's think about the higher dimensional forms as a vector, i.e. vec(u). In this case, what is the matrix A for which reshape(A*vec(u),size(u)...) performs the higher dimensional Laplacian, i.e. $u_{xx} + u_{yy}$? The answer is that it discretizes via Kronecker products to:
\[ A=I_{y}\otimes A_{x}+A_{y}\otimes I_{x} \]
or:
\[ \frac{\partial^{2}}{\partial x^{2}}=\left(\begin{array}{cccc} A_{x}\\ & A_{x}\\ & & \ddots\\ & & & A_{x} \end{array}\right) \]
and
\[ \frac{\partial^{2}}{\partial y^{2}}=\left(\begin{array}{cccc} -2I_{x} & I_{x}\\ I_{x} & -2I_{x} & I_{x}\\ & & \ddots\\ \\ \end{array}\right) \]
To see why this is the case, understand it again as the stencil operation
0 1 0
1 -4 1
0 1 0In this operation, at a point you still use the up and down neighbors, and thus this has a tridiagonal form since those are the immediate neighbors, but the next $y$ value is $N$ over, so this is where the block tridiagonal form comes for the stencil in the $y$ terms. When these are added together one receives the appropriate matrix. The Kronecker product effectively encodes this "N over" behavior. It also readily generalizes to $N$ dimensions. To see this for 3-dimensional Laplacians, $u_{xx} + u_{yy} + u_{zz}$, notice that
\[ A=I_z \otimes I_{y}\otimes A_{x} + I_z \otimes A_{y}\otimes I_{x} + A_z \otimes I_y \otimes I_x \]
using the same reasoning about "N" over and "N^2 over", and from this formulation it's clear how to generalize to arbitrary dimensions.
We note that there is an alternative representation as well for 2D forms. We can represent them with left and right matrix operations. When $u$ is represented as a matrix, notice that
\[ A(u) = A_y u + u A_x \]
where $A_y$ and $A_x$ are both the [1 -2 1] 1D tridiagonal stencil matrix, but by right multiplying it's occurring along the columns and left multiplying occurs along the rows. This then gives a semi-dense formulation of the stencil operation.
Implementation via Stencil Compilers
Sparse matrix implementations of stencils are fairly inefficient given the way that sparse matrices are represented (lists of (i,j,v) pairs, which are then compressed into CSR or CSC formats). However, it moves in the right direction by noticing that the operation
u[i+1,j] + u[i,j+1] + u[i-1,j] + u[i,j-1] - 4u[i,j]is an inefficient way to walk through the data. The reason is because u[i,j+1] is using values that are far away from u[i,j], and thus they may not necessarily be in the cache.
Thus what is generally used is a stencil compiler which generates functions for stencil operations. These work by dividing the tensor into blocks on which the stencil is applied, where the blocks are small enough to allow the cache lines to fit the future points. This is a very deep computational topic that is beyond the scope of this course. Note one of the main reasons why NVIDA's CUDA dominates machine learning is because of its cudnn library, which is a very efficient GPU stencil computation library that is specifically tuned to NVIDIA's GPUs.
Cross-Discipline Learning
Given these relations, there is a lot each of the disciplines can learn from one another about stencil computations.
What ML can learning from SciComp: Stability of Convolutional RNNs
Stability of time-dependent partial differential equations is a long-known problem. Stability of an RNN defined by stencil computations is then stability of Euler discretizations of PDEs. Let's take a look at Von Neumann analysis of PDE stability.
Let's look at the error update equation. Write
\[ e_{i}^{n}=u(x_{j},t_{n})-u_{j}^{n} \]
For $e_{i}^{n}$, as before, plug it in, add and subtract $u(x_{j},t^{n})=u_{j}^{n}$, and then we get
\[ e_{i}^{n+1}=e_{i}^{n}+\mu\left(e_{i+1}^{n}-2e_{i}^{n}+e_{i-1}^{n}\right)+\Delta t\tau_{i}^{n} \]
where
\[ \tau_{i}^{n}\sim\mathcal{O}(\Delta t)+\mathcal{O}(\Delta x^{2}). \]
Stability requires that the homogenous equation goes to zero. Another way of saying that is that the propagation of errors has errors decrease their influence over time. Thus we look at:
\[ e_{i}^{n+1} =e_{i}^{n}+\mu\left(e_{i+1}^{n}-2e_{i}^{n}+e_{i-1}^{n}\right) =\left(1-2\mu\right)e_{i}^{n}+\mu e_{i+1}^{n}+\mu e_{i-1}^{n} \]
A necessary condition for decreasing is then for all coefficients to be positive
\[ 1-2\mu\geq0 \]
or
\[ \mu\leq\frac{1}{2} \]
A more satisfying way may be to look at the generated ODE
\[ u^{\prime}=Au \]
where A is the matrix $\left[\mu,1-2\mu,\mu\right].$
But finding the maximum eigenvalue is non-trivial. But for linear PDEs, one nice way to analyze the stability directly is to use the Fourier mode decomposition. This is known as Van Neumann stability analysis. To do this, decompose $U$ into the Fourier modes:
\[ U(x,t)=\sum_{k}\hat{U}(t)e^{ikx} \]
Since
\[ x_{j}=j\Delta x, \]
we can write this out as
\[ U_{j}^{n}=\hat{U}^{n}e^{ikj\Delta x} \]
and then plugging this into the FTCS scheme we get
\[ \frac{\hat{U}^{n+1}e^{ikj\Delta x}-\hat{U}^{n}e^{ikj\Delta x}}{\Delta t}=\frac{\hat{U}^{n}e^{ik(j+1)\Delta x}-2\hat{U}^{n}e^{ikj\Delta x}+\hat{U}^{n}e^{ik(j-1)\Delta x}}{\Delta x^{2}} \]
Let G be the growth factor, defined as
\[ G=\frac{\hat{U}^{n+1}}{\hat{U}^{n}} \]
and thus after cancelling we get
\[ \frac{G-1}{\Delta t}=\frac{e^{ik\Delta x}-2+e^{-ik\Delta x}}{\Delta x^{2}} \]
Since
\[ e^{ik\Delta x}+e^{-ik\Delta x}=2\cos\left(k\Delta x\right), \]
then we get
\[ G=1-\mu\left(2\cos\left(k\Delta x\right)-2\right) \]
and using the half angle formula
\[ G=1-4\mu\sin^{2}\left(\frac{k\Delta x}{2}\right) \]
In order to be stable, we require
\[ \left|G\right|\leq1, \]
which means
\[ -1\leq1-4\mu\sin^{2}\left(\frac{k\Delta x}{2}\right)\leq1 \mu>0 \]
and so $\leq1$ is simple. Since $\sin^{2}(x)\leq1$, then we can simplify this to
\[ -1\leq1-4\mu \]
and thus $\mu\leq\frac{1}{2}$. With backwards Euler we get
\[ \frac{G-1}{\Delta t}=\frac{G}{\Delta x^{2}}\left(e^{ik\Delta x}-2+e^{-ik\Delta x}\right) \]
and thus get
\[ G+4G\mu\sin^{2}\left(\frac{k\Delta x}{2}\right)=1 \]
and thus
\[ G=\frac{1}{1+4\mu\sin^{2}\left(\frac{k\Delta x}{2}\right)}\leq1. \]
What SciComp can learn from ML: Moderate Generalizations to Partial Differential Equation Models
Instead of using
\[ \Delta u = f \]
we can start with
\[ S[u] = f \]
a stencil computation, predefined to match a known partial differential equation operator, and then transfer learn the stencil to better match data. This is an approach which is starting to move down the lines of physics-informed machine learning that will be further explored in future lectures.